A Survey on Session-based Recommender Systems
本文是ACM’18关于session-based recommender systems(SBRS)的综述,文章对SBRS的推荐范式进行了说明,从理论和实践上证明了SBRS的价值;对当前对SBRS进行了系统分类,并从技术及研究的角度对其进行说明;最后总述了SBRS目前的进展及其复杂性和挑战。
推荐系统分类
| 推荐系统 | 输入 | 核心假设 | 工作机制 | 优势 | 劣势 |
|---|---|---|---|---|---|
| 基于内容 | user和item content | 根据用户的 喜好做推荐 | 根据item content建模 | 简单直接 可以解决用户的冷启动 | 用户兴趣会变化,跟现实场景会有出入 |
| 协同过滤(CF) | User-item交互数据 | 根据用户喜好 | User-item交互数据建模 | 有效且相对简单 | 容易陷入数据稀疏带来的问题, 冷启动问题 |
| 上下文可感知的RS | User, item, 上下文,user-item交互数据 | 用户在不同上下文环境下有不同的喜好 | 对User-item 上下文 交互信息进行建模 | User-item交互数据建模 | 可用数据及数据稀疏的问题 |
| SBRS | Session的数据 | 用户的喜好随着session的变化而变化 | 推荐出现在相似的session环境中的items | 考虑到用户喜好的变化,更好的符合现实场景 | 会忽略用户长期的更general的喜好 |
SBRS相关定义及符号表示
定义如下符号表示:
用户:u
用户集合: $U=\left\{u_{1}, u_{2}, \ldots, u_{|U|}\right\}$
物品: i
物品集合:$I=\left\{i_{1}, i_{2}, \ldots, i_{|I|}\right\}$
session: $s=\left\{i_{1}, i_{2}, \ldots, i_{|s|}\right\}$
session集合: $S=\left\{s_{1}, s_{2}, \dots, s_{|S|}\right\}$
待预测/推荐物品为: t
Intra-session context: $C^{I a}$
Inter-seesion context: $C^{I e}$
session的定义: 一段时间内用户消费/收集的一系列事件内的item集合
SBRS定义: SBRS的任务是给定session的部分信息对未知/未来的信息进行预测。
Intra-session context定义: $s_{n}$为当前待推荐session,则$C^{I a}=\left\{i | i \in s_{n}, i \neq i_{t}\right\}$
Inter-session context定义: $s_{n}$为当前待推荐session,$C^{I e}=\left\{s_{n-1}, s_{n-2}, \dots, s_{\left|c^{I e}\right|}\right\}$
session-based recommendation task定义: 给定一个session语境C,session-based recommendation是学习一个从C到t的函数f使得$t: t \Leftarrow f(C)$。在SBRS中,session context是首要的信息,其他如用户或item信息也可以添加到模型中。
Next-items recommendation: 给定当前session $s_{n}$和intra-session context$C^{Ia}$预测$i_{t}$
Next-sessopm(next-basket) recommendations: 给定当前session$s_{n}$和inter-session context $C^{Ie}$预测下一个session的items。
SBRS的意义,复杂性和挑战
- 意义和价值: SBRS在学术和商业上都具有重要意义。
复杂性:
数据的复杂性
如下图所示,数据可以分为如下五个等级,SBRS需要的是中间核心的三个(item feature level, item level 和session level)。
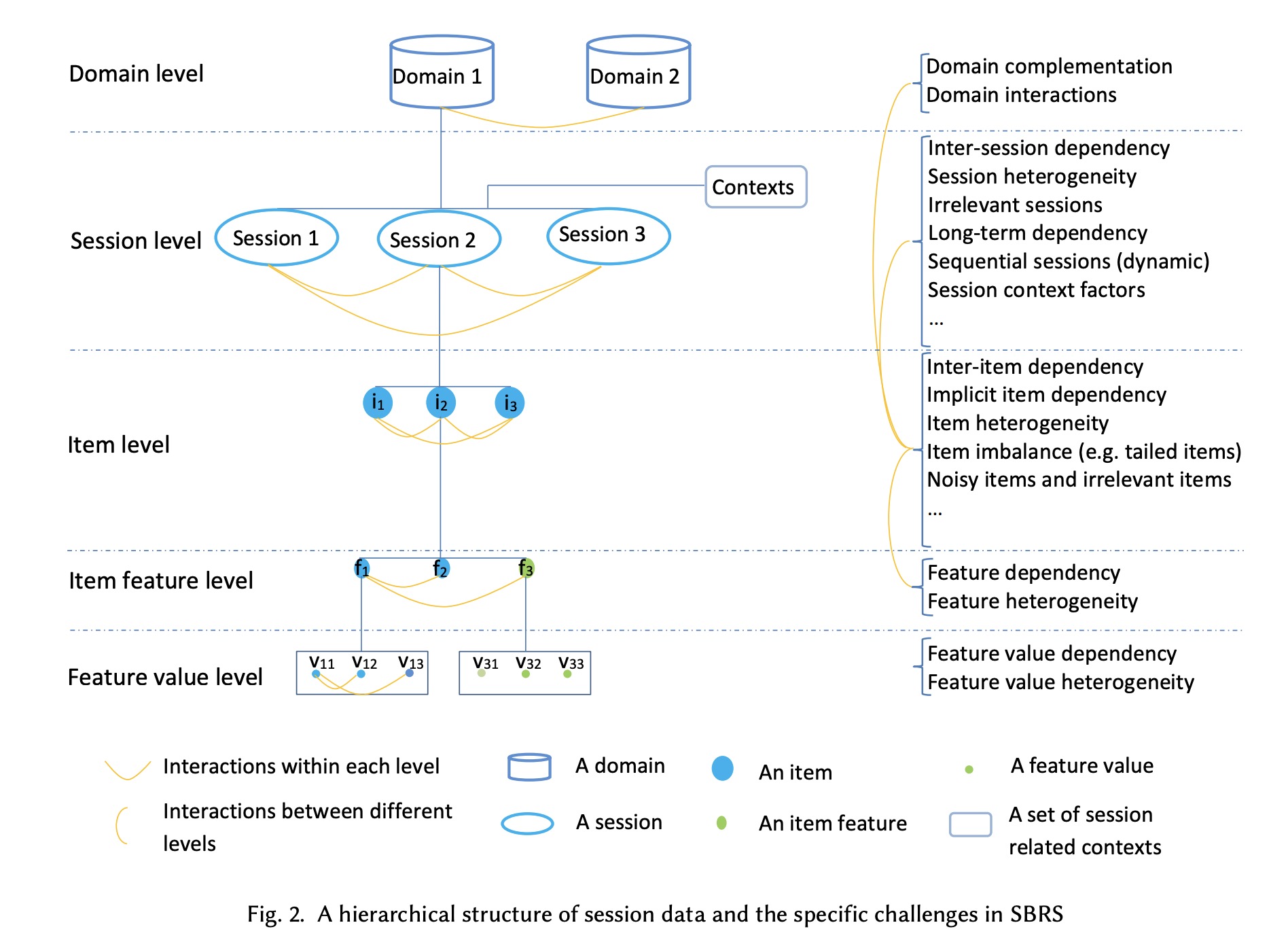
挑战: 上图右侧描述了每层的一些挑战,按照层级可以分为 Inner-session,Inter-session, Outer-session的挑战。也可以按照类别分为异质性,共生性,复杂性和相互作用四大类。
Overview of SBRS
SBRS的发展可以分为两阶段: 1990s到2010s的model-free阶段,主要依赖pattern或规则去做。第二阶段是从2010s到现在的model-based阶段,主要采用统计和机器学习算法来做,包括时序相关的马尔可夫链,rnn等。
SBRS的分类和总结
从研究问题的角度做分类
按照推荐什么做分类:
- Next-item: 有明显session划分的预测下一个
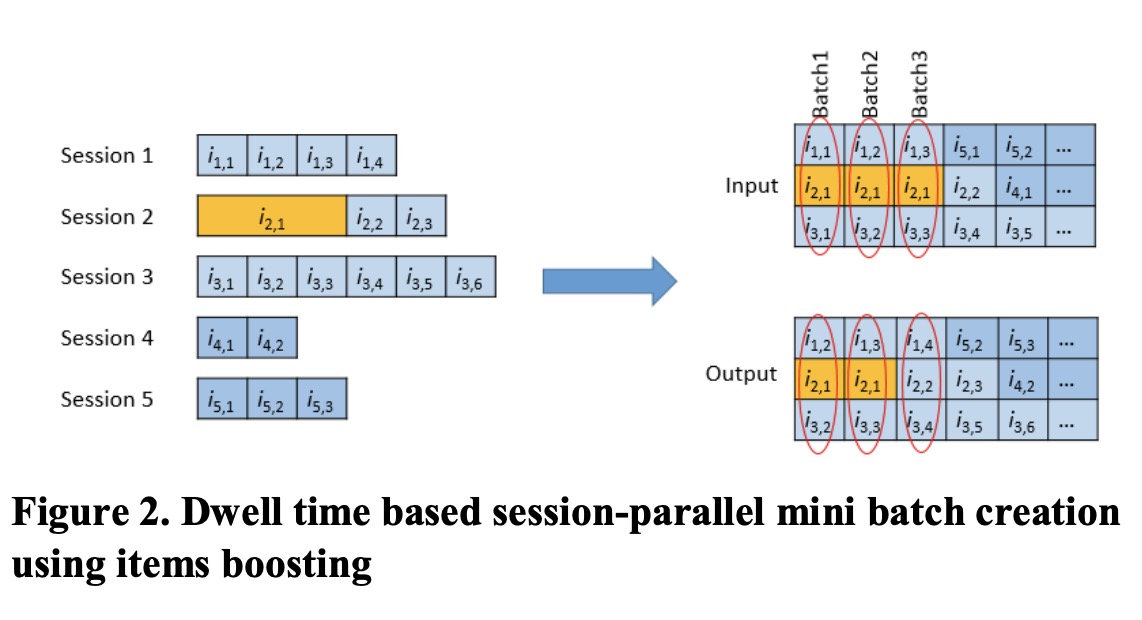
- Incorporating dwell time in session-based recommendations with recurrent Neural networks 2017
- Recurrent Latent Variable Networks for Session-Based
Recommendation 2017 - A Variational Recurrent Neural Network for Session-Based
Recommendations using Bayesian Personalized Ranking2017 - Web path recommendations based on page ranking and
markov models 2005 - Web page personalization based on weighted association rules 2009
- Session-based recommendations using item embedding 2017
- Recurrent Neural Networks with Top-k Gains for Session-based Recommendations 2017
- Session-based recommendations with recurrent
neural networks 2015 - Parallel recurrent neural network architectures
for feature-rich session-based recommendations 2016 - Diversifying personalized recommendation
with user-session context 2017 - When recurrent neural networks meet the neighborhood for session-based recommendation 2017
- Session-based item recommendation in e-commerce: on short-term intents,reminders, trends and discounts 2017
- Factorization meets the item embedding: Regularizing matrix
factorization with item co-occurrence 2016 - Interacting Attention-gated Recurrent Networks
for Recommendation2017 - Personalizing Session-based Recommendations
with Hierarchical Recurrent Neural Networks 2017 - Inter-Session Modeling for Session-Based Recommendation 2017
- Improved recurrent neural networks for session-based recommendations2016
- Perceiving the Next Choice with Comprehensive Transaction Embeddings for Online Recommendation 2017
- Attention-based Transactional Context
Embedding for Next-Item Recommendation 2018 - Effective next-items recommendation via personalized sequential pattern mining 2012
- Sequential
Recommender System based on Hierarchical Attention Networks 2018
- Next-basket: 有明显session划分的预测下一个session
- Next-event/action: 无明显session划分
- Content-Aware Hierarchical Point-of-Interest
Embedding Model for Successive POI Recommendation 2018 - Where You Like to Go Next: Successive Point-of-Interest Recommendation 2013
- Addressing cold start for next-song recommendation 2016
- Personalized Ranking Metric Embedding
for Next New POI Recommendation 2015 - Collaborative filtering meets next check-in location prediction 2013
- K-plet Recurrent Neural Networks for Sequential Recommendation 2018
- Personalized next-song recommendation in
online karaokes 2013
- Content-Aware Hierarchical Point-of-Interest
- Next-item: 有明显session划分的预测下一个
按照如何推荐做分类:
| 方法 | 进展 | 缺点 |
|---|---|---|
| Item-level dependency modeling | patten-based, 马尔可夫链模型, RNN, attention | item 不平衡(如热门商品),长尾商品 |
| Session-level dependency modeling | 因子分解机, RNN等 | 长期依赖,上下文感知,inter-seesion依赖 |
| Feature-level dependency modeling | 因子分解机, RNN, CNN | 特征的异构和依赖 |
| Feature value-level dependency modeling | 目前没有进展 | 特征值的异构和依赖,item-feature-value的交互 |
| Domain-level dependency modeling | 目前没有进展 | Domain间的互补和交互 |
从技术的角度进行分类
model-free方法
model-free的方法主要包括:
- 基于pattern/规则
- 基于序列pattern
model-based 方法
model-based 方法包括:
- 基于马尔可夫链的推荐,基于转移概率考虑一阶依赖。
- 因子分解机,首先将共现矩阵或item-item转移矩阵进行分解,得到item的隐变量,基于隐变量做推荐。
- 基于神经网络的方法,如考虑序列的RNN等。
model-free方法介绍
基于pattern/规则的推荐系统主要分三阶段:1.最高频的pattern挖掘,session匹配和item推荐。
常见的基于高频pattern的挖掘有Apriori,FR-Tree及相关变形。
基于session pattern的方法和高频pattern 的挖掘相似,但是有一下两个不同点:1.主要考虑inter-seesion的信息而不是intra-session的信息。2.是对序列信息进行挖掘的。
model-based 方法介绍
基于马尔可夫链的推荐方法
马尔可夫链模型可以描述为$\left\{S T, P_{t}, P_{0}\right\}$,其中ST为状态空间,$P_{t}$为状态转移矩阵,$P_{0}$为初始状态概率,一阶状态转移概率为:
$P_{t}(j, k)=P\left(i_{j} \rightarrow i_{k}\right)=\frac{f r e q\left(i_{j} \rightarrow i_{k}\right)}{\sum_{i_{t} \in I} f r e q\left(i_{j} \rightarrow i_{t}\right)}$
由上述公式我们可以得到$\{i_{1}\rightarrow i_{2} \rightarrow i_{3}\}$的概率为:
$P\left(i_{1} \rightarrow i_{2} \rightarrow i_{3}\right)=P\left(i_{1}\right) P\left(i_{2} | i_{1}\right) P\left(i_{3} | i_{2}\right)$
通过上述公式我们可以计算给定session 部分序列时某一item的概率从而做推荐。
除了上述基本的模型外,有其他一些变形,包括结合一阶二阶马尔可夫的模型,有结合隐马尔可夫的概率模型,还有结合因子分解做一些工作。
基于因子分解机的推荐方法
由上述可知,根据观测数据可以计算转移概率,从而形成转移概率矩阵$A^{u}$,需要注意的是上述转移概率矩阵是某一个用户的,因此所有用户的概率转移矩阵为$\mathfrak{A}^{|U| \times|I| \times|I|}$,最基本的因子分解模型是基于Tucker降维:
$\hat{\mathscr{H}}=C \times V_{U} \times V_{I_{j}} \times V_{I_{k}}$
其中C为核张量,$V_{U}$为用户特征矩阵,$V_{I_{j}}$,$V_{I_{k}}$分别为当前item的特征矩阵和下一个item的特征矩阵。
基于神经网络的推荐方法
基于神经网络的推荐方法主要分两大类:基于embedding的浅层的神经网络推荐模型和多层的深度神经网络推荐模型。
浅层神经网络
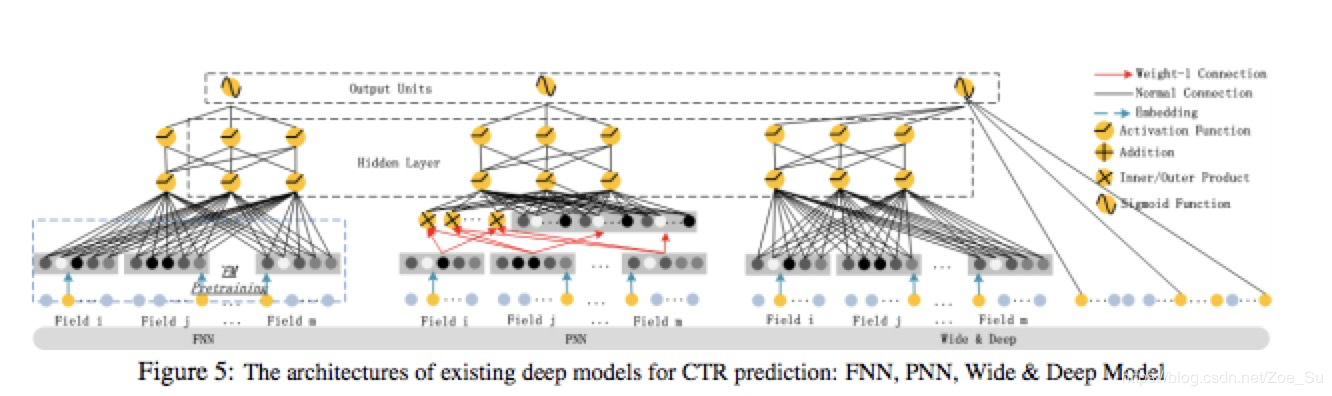
主要是受到word2vec的启发,这种方法将item序列理解为句子,item为词,使用同word2vec的方法可以学习得到高维空间中item的表示,从而item embedding的距离可以表示为他们的关系,基于此做推荐。其他的变形包括加入item feature或其他相关feature做embedding,或加入attention机制,都是自然语言中常见的几种方法。
深层神经网络
深层神经网络主要从2016年开始,主要包括基于RNN的,基于DNN的和基于CNN的。
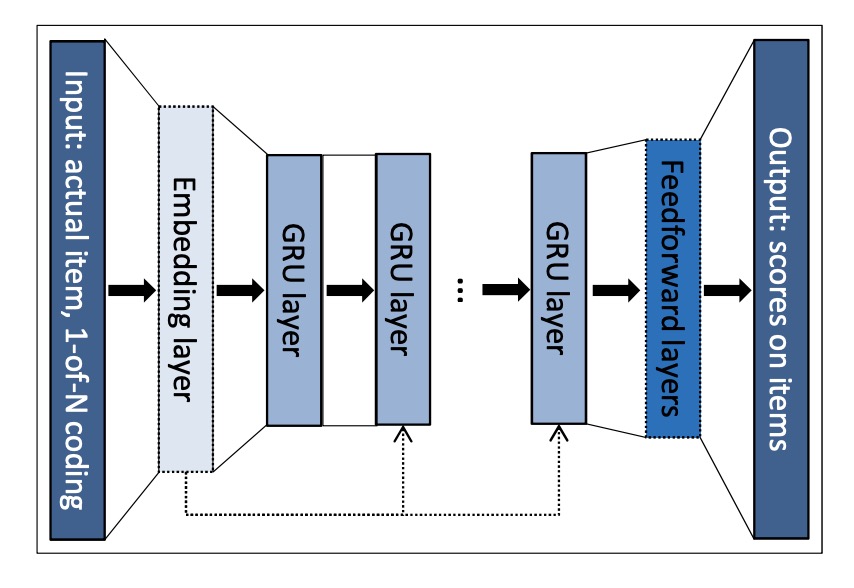
基于RNN: 更好得捕捉序列关系
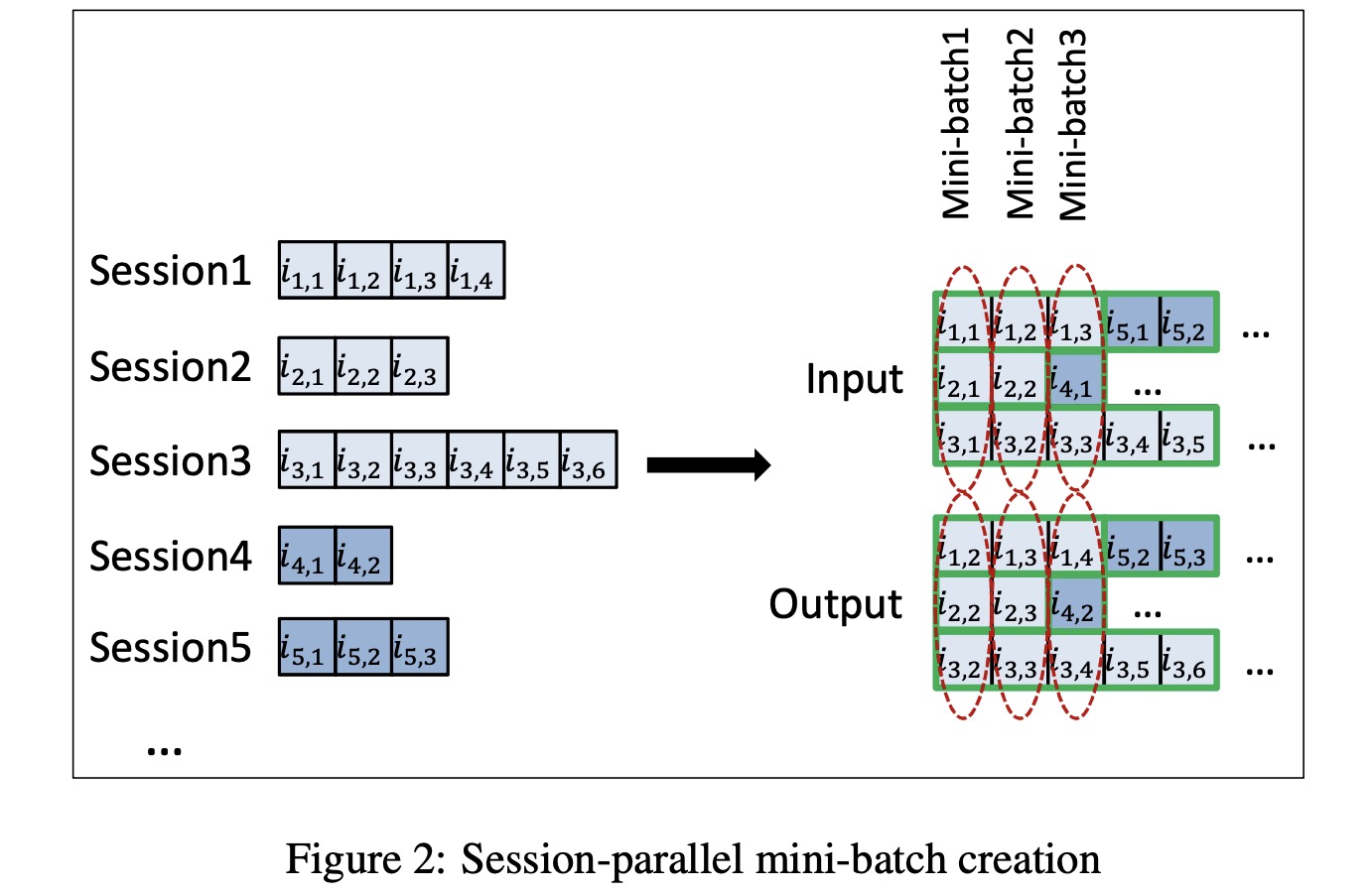
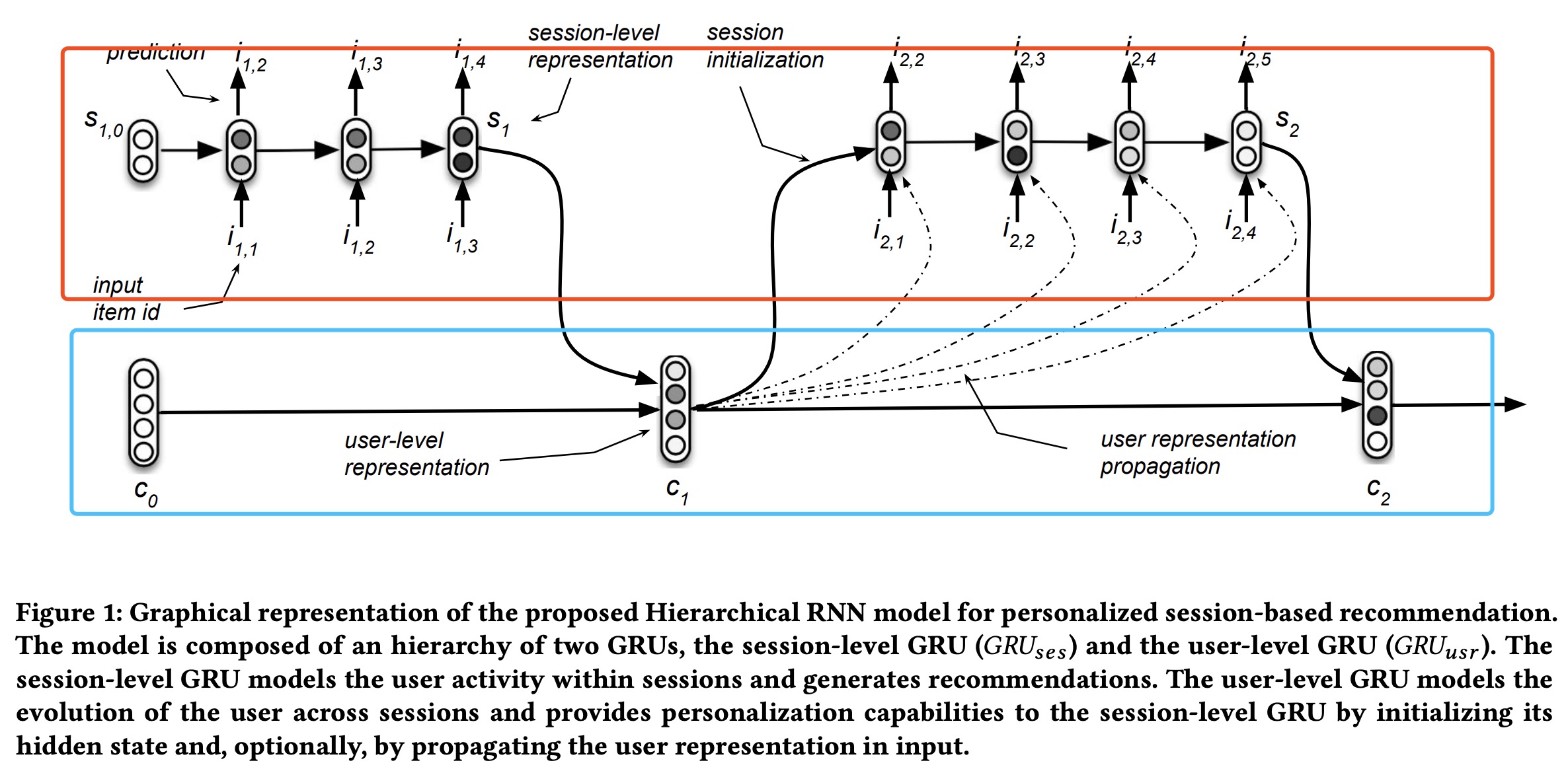
最基础的是GRU4REC模型,输入item序列,输出item的概率分布(同最基础的语言模型)。为提升GRU4REC的效果,Tan提出数据增广和embedding dropout两种策略训练GRU4REC模型,同时提出一个generalised distillation framework;Quadrana提出层次RNN结构来捕捉跨session 的信息;Tim Donkers提出结合用户属性的user-based GRU来产生用户个性化推荐。
除了基于GRU4REC的推荐模型,还有基于RNN的一些变形模型,如Dynamic REcurrent bAsket Model (DREAM),通过每个时刻的隐状态学习用户变化的表示。
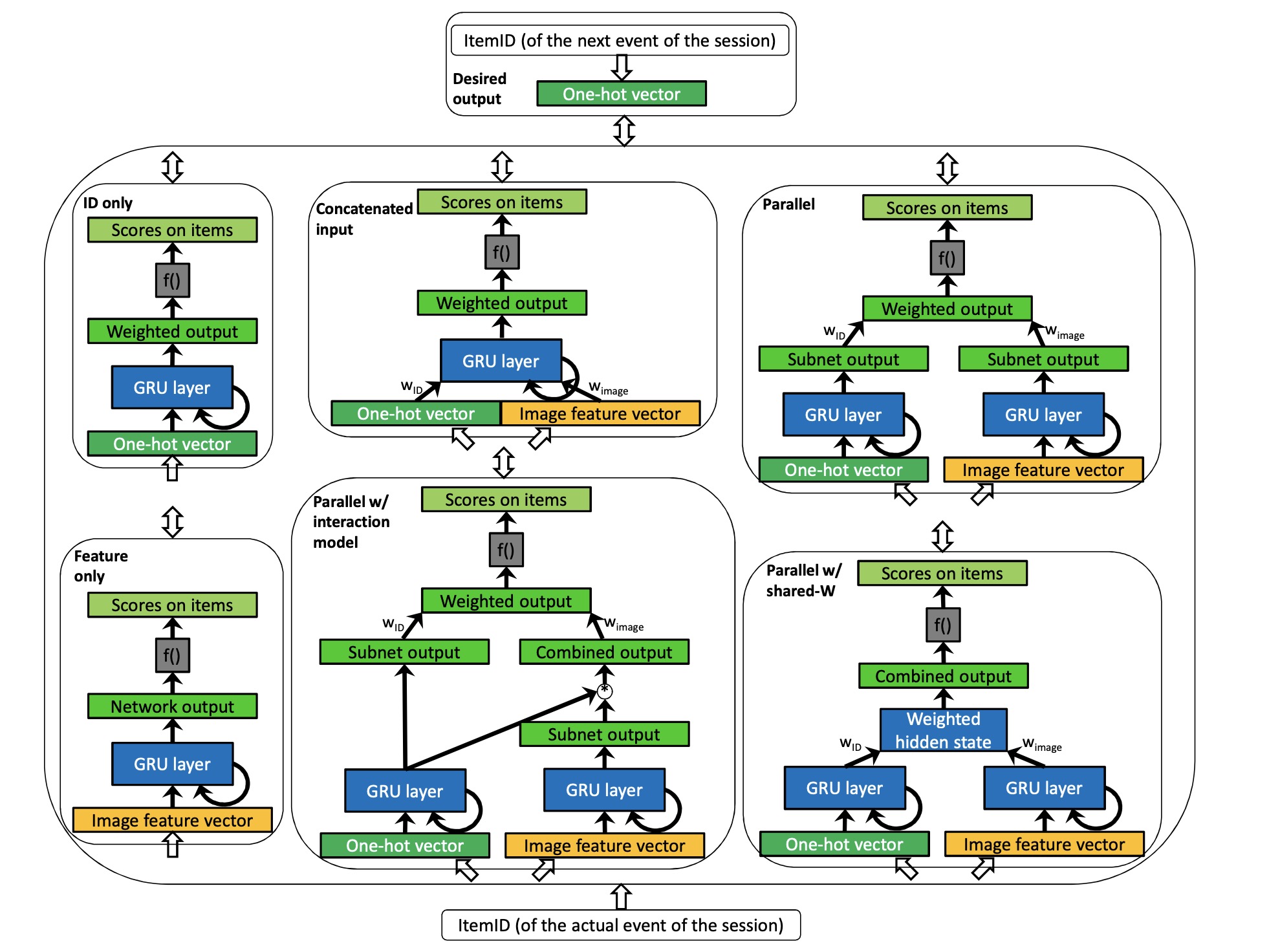
其他的一些进展包括:1.RNN结合变分推断解决稀疏数据的不确定性和降低模型规模[2,3];2.结合更丰富的信息如上下文信息,位置,item feature等来提升模型的效果[4,5,6];3.加入attention机制7;4.结合传统的FM或KNN等模型
基于DNN:常用于当一个session中无序列关系时,如一个购物车中的物品。
基于CNN:同样适用于无严格序列关系的session数据,并且具有更强的局部特征的捕捉能力,可以跨区域捕捉RNN常常捕捉不到的联合依赖关系。
参考文献
Recurrent Latent Variable Networks for Session-Based
Recommendation- A Variational Recurrent Neural Network for Session-Based
Recommendations using Bayesian Personalized Ranking - Latent Cross: Making Use of Context in
Recurrent Recommender Systems - Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
- Incorporating Dwell Time in Session-Based Recommendations with Recurrent Neural Networks
- Interacting Attention-gated Recurrent Networks for Recommendation