Doc2vec
常用于短文本向量化的方法包括:
- Bag of words
- LDA
- Average word vectors
- tfidf-weighting word vector
上述方法存在公共的问题是没有考虑单词的顺序。而本文介绍的doc2vec是2014年谷歌的两位大牛Quoc Le 和 Tomas Mikolov提出的。文章提出一种无监督学习模型通过预测句子/段落中word来得到句子/段落/文档的向量表示。
模型
word2vec
文章提出的得到句子/段落/文档向量的方法是受到word2vec的启发,因此先回顾一下word2vec。如下图所示,word2vec是通过给定单词预测另一个单词,如CBOW根据前后词预测中间词,以及Skip-gram根据中间词预测前后词。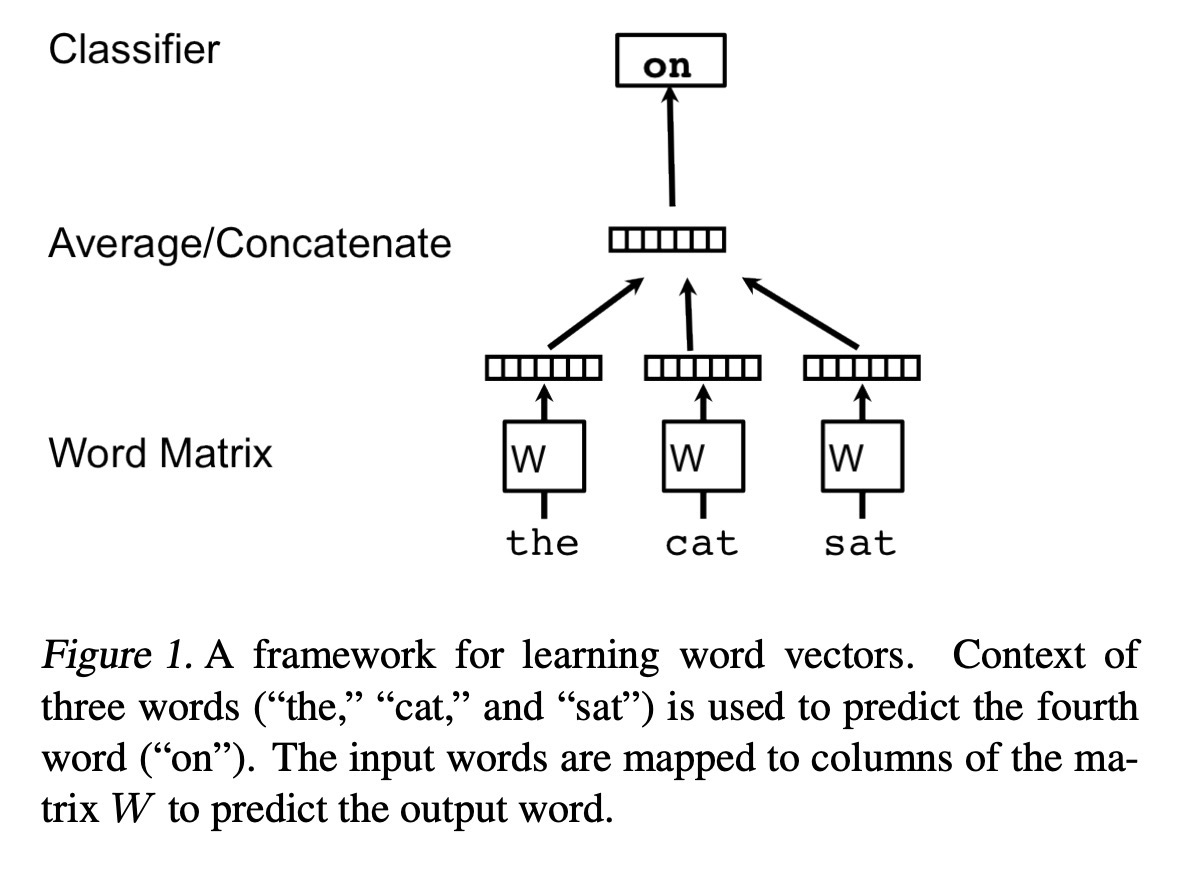
在模型中,每个词都用唯一的向量表示,是通过一个W矩阵通过index索引得到的每个词的向量表示,通过concat/average所有词的向量表示作为feature去预测另外一个词。在CBOW中,通过前后词预测中间词,模型最终优化的是最大化给定前后词的条件下当前词出现的概率,即:
最终模型通过softmax得到每个词出现的概率:
上式中的$\boldsymbol{y}_{i}$是未归一化的每个词出现的概率:
原始论文中还提到使用层次softmax代替softmax来提升训练速度。详细细节见原文.
Paragraph Vector: A distributed memory model
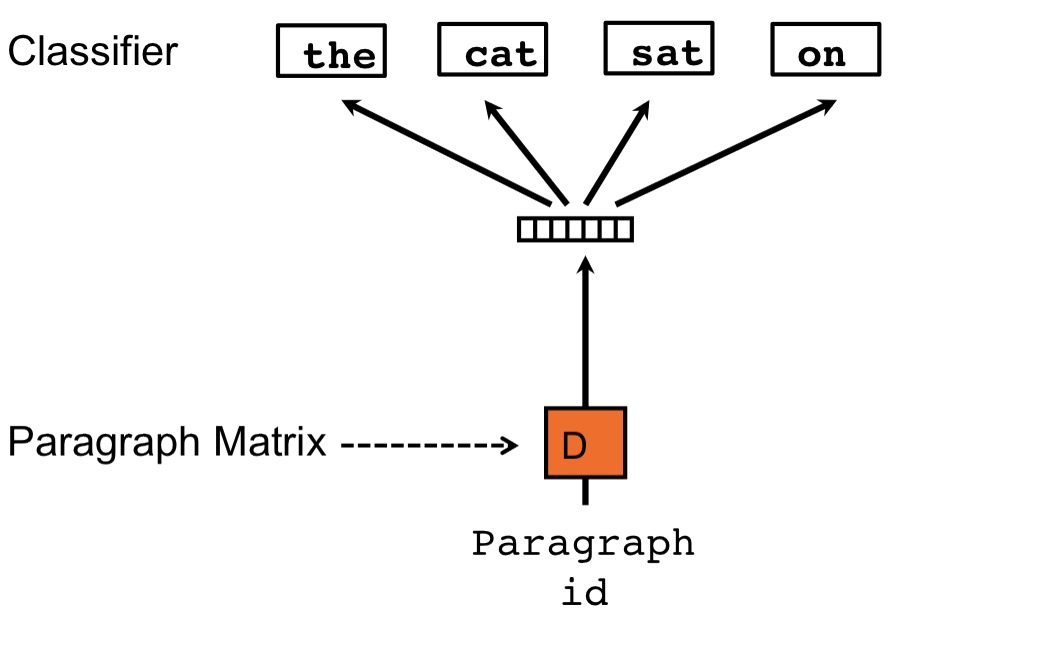
受word2vec的启发,Paragraph Vector也是通过给出上下文预测下一个word来进行学习的,对应的框架如下: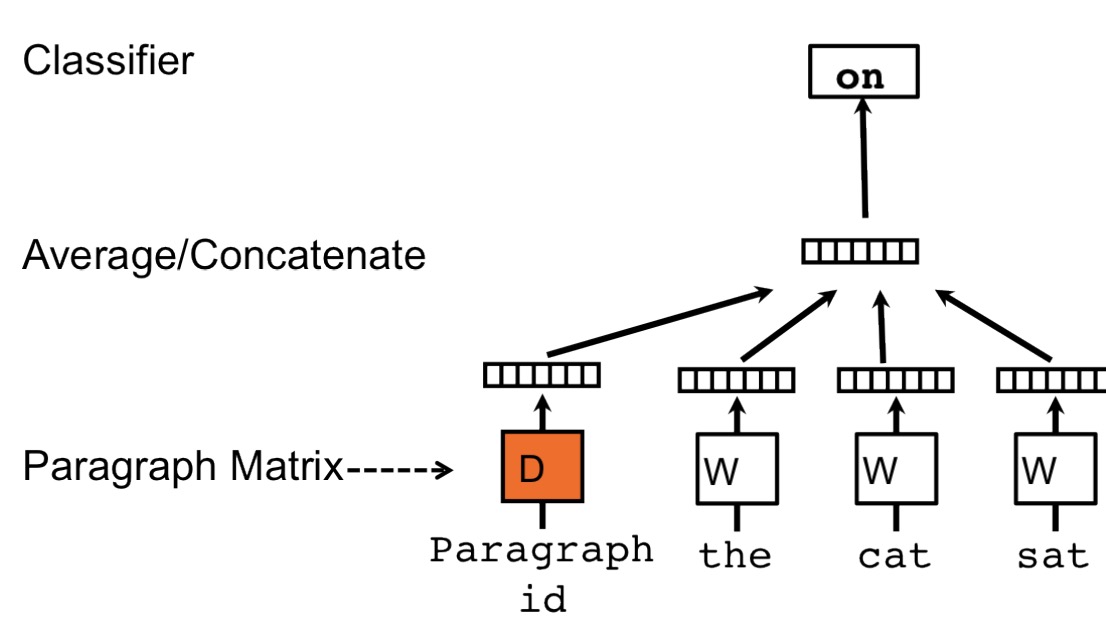
每个段落/句子通过矩阵D映射到向量空间中,用D的一列代替,同样,每个单词也被映射到向量空间,用矩阵W的一列表示,然后通过段落/句子向量和词向量级连或求平均得到特征预测下一个单词。与word2vec唯一不同的是在计算$y_{i}$时的h是通过W和D average/concat 得到的。
对于D我们可以理解为其他的word,它相当于是上下文的记忆单元活着这个段落的主题,因此我们叫这种训练方法为Distributed Memory Model of Paragraph Vector(PV-DM)。在训练时,通常采用固定长度的滑动窗口得到训练集,段落/句子向量在上下文中是共享的。
总结doc2vec的过程主要是两步:
- 训练阶段,在已知数据集上训练得到模型参数D,W,U,b
- 预测阶段,得到未知段落的向量D即在固定W,U,b的情况下利用上述方法进行梯度下降,得到新的D(D中会加入表征新段落的column)
优点:
- 使用无监督学习,不需要大量有标记数据
- 能够解决bag-of-words模型的缺点:
- 能够学到词之间的语义信息
- 考虑到了词之间的顺序
Paragraph Vector without worf ordering: Distributed bag of words
上面提到的训练方法是要综合paragraph vector和word vector去预测下一个词,另一种训练方法可以忽略词的上下文来预测随机从段落/句子采样得到的一个词,具体来说就是每次迭代训练时,采样一个窗口的文本,然后从窗口文本中随机选一个词做预测。我们称这种方法为Distributed Bag of Words version of Paragraph Vector(PV-DBOW)。模型架构如下: