EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction
这篇[文章][10]很早就看到过,但是到2019年6月份才发表出来,本文章认为目前的知识追踪的model都只用了学生的做题信息,而其他的如知识概念或习题内容相关的知识并没有在model中引入,而引入这些信息是能够为模型的预测精度带来增益的,因此作者提出Exercise-Enhanced Recurrent Neural Network(EERNN),在这个模型中,不仅使用了学生的做题记录,还引入了习题的文本信息。在EERNN中,作者使用RNN的隐变量来表征学生的学习轨迹,使用BiLSTM来学习习题的编码信息。在最终predict阶段,作者在EERNN基础上采用了两种策略,一种是EERNNM with Markov property,另一种是EERNNA with attention mechanism。最终为了追踪学生在各知识点上的掌握情况,作者将EERNN引入知识概念的信息引入得到Exercise-Aware Knowledge Tracing(EKT)。
模型:
模型主要分两部分来描述,一是做预测的EERNN(EERNNM & EERNNA),另一部分是追踪学生知识掌握情况的EKT。
EERNN
EERNN的提出主要用于做学生performance的预测,基于不同的策略又分为EERNNM和EERNNA。网络结果如下图所示:
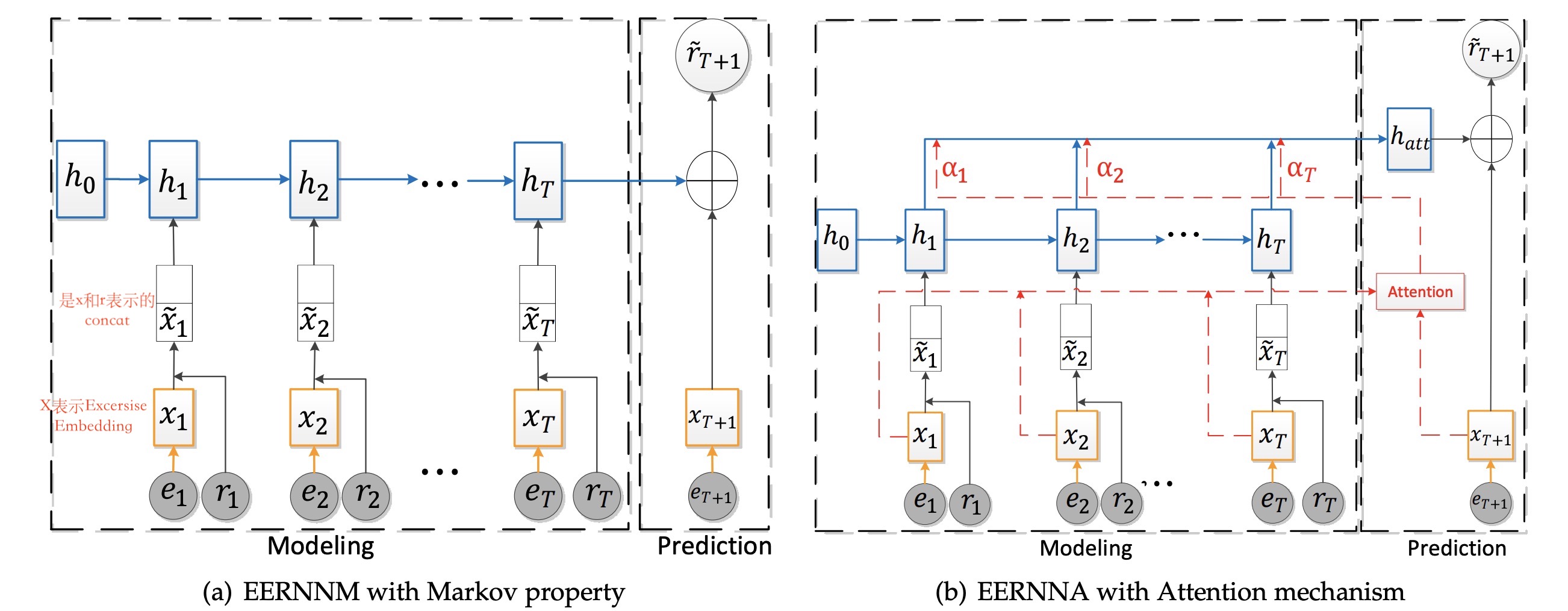
从上图可以看出:EERNNM和EERNNA的区别主要在prediction阶段,图中橘色框表示的是题目的embeddig,蓝色框表示的是学生的embedding。
Exercise embedding:
Exercise embedding的获取是通过双向LSTM得到的,结构如下: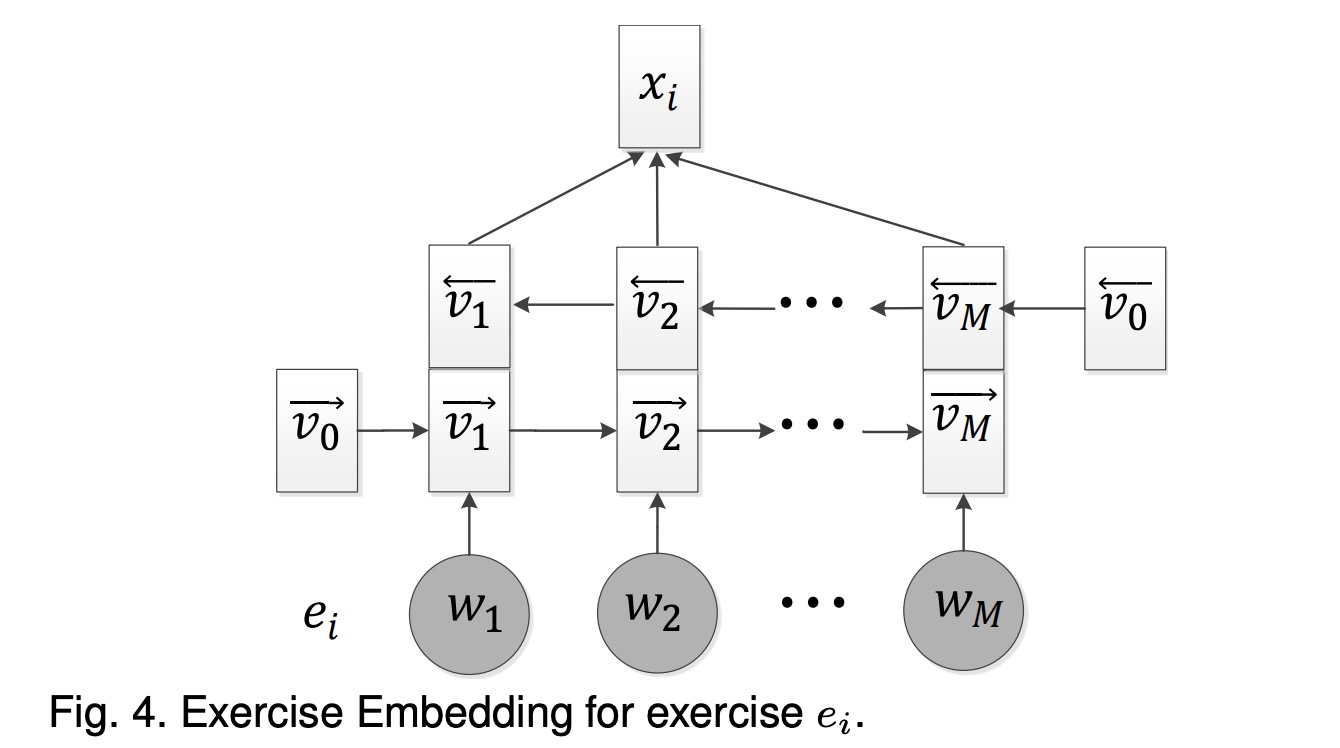
通过上述可以得到每个word的embedding $v_{m}=$ concatenate $\left(\vec{v}_{m}, \overleftarrow v_{m}\right)$,最终Exercise的embedding是通过max-pooling每个word的embedding得到,即$x_{i}=\max \left(v_{1}, v_{2}, \ldots, v_{M}\right) x_{i} \in \mathbb{R}^{2 d_{v}}$。
Student Embedding:
表征学生的向量应该跟题目和学生的回答有关,因此作者在上面获得$x_{i}$的基础上加入了表示学生作答情况的信息,通过RNN/LSTM得到student embedding,具体实现是首先将$r_{t}$表示成一个$2 d_{v}$维的$\mathbf{0}=(0,0, \ldots, 0)$,最终输入$\widetilde{x}_{t} \in \mathbb{R}^{4 d_{v}}$表示为:
Prediction
EERNNM:
基于markov性,下一时刻状态的条件概率分布只与当前状态有关,因此对$\widetilde{r}_{T+1}$的预测只与$h_{T}$和$x_{T+1}$有关,因此计算公式如下:
$\begin{aligned} y_{T+1} &=\operatorname{Re} L U\left(\mathbf{W}_{1} \cdot\left[h_{T} \oplus x_{T+1}\right]+\mathbf{b}_{1}\right) \\ \widetilde{r}_{T+1} &=\sigma\left(\mathbf{W}_{2} \cdot y_{T+1}+\mathbf{b}_{2}\right) \end{aligned}$ ... (1) EERNNA
如果序列很长的话,LSTM捕捉信息的能力会降低,因此为了改善上述问题,引入常用的Attention机制。
经过attention后的表征当前状态的隐变量变为:$h_{a t t}=\sum_{j=1}^{T} \alpha_{j} h_{j} \\ \alpha_{j}=\cos \left(x_{T+1}, x_{j}\right)$
将(1)式中的$h_{a t t}$替换$h_{T}$即可得到预测结果。
EKT: Exercise-aware Knowledge Tracing
EKT本质做的是将原始EERNN学习到的学生状态从$h_{t} \in \mathbb{R}^{d_{h}}$变换成$\dot{H}_{t} \in \mathbb{R}^{\dot{d}_{h} \times K}$,也就是说用一个向量来表征学生对某个知识的掌握情况。模型结构如下图所示: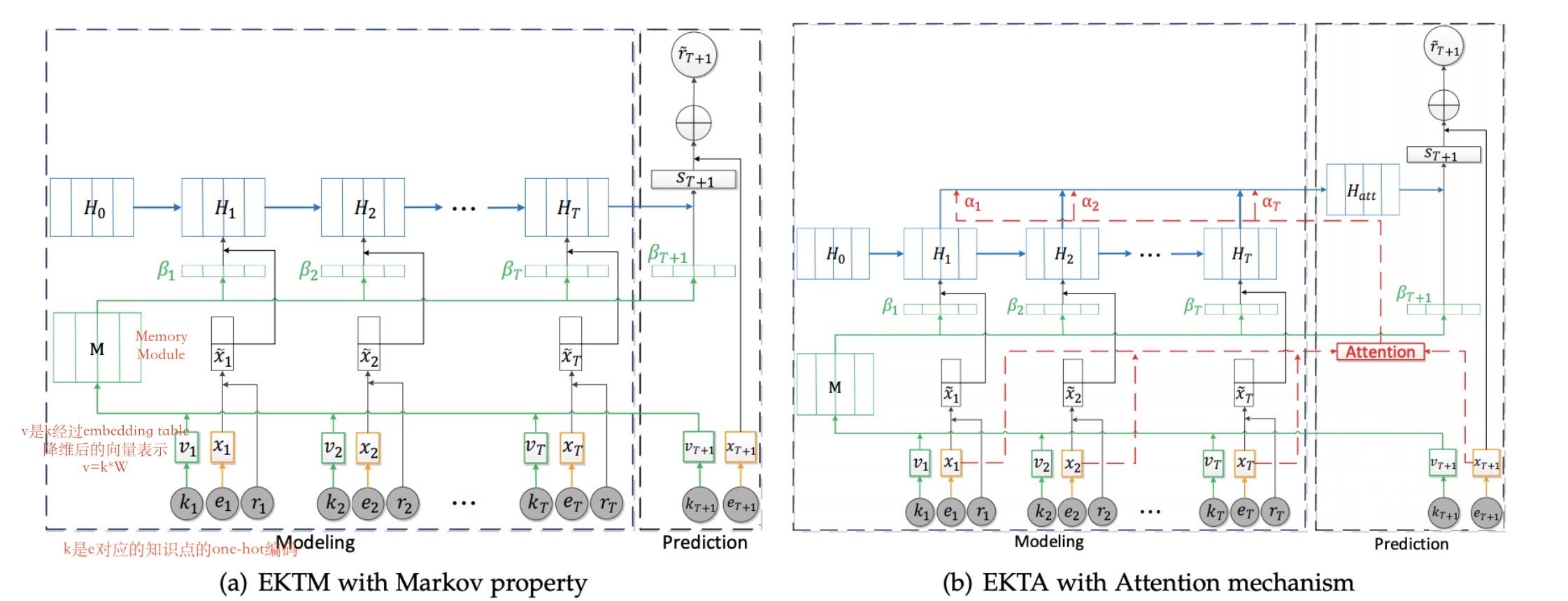
与EERNN相比,除了使用到Exercise Embedding还用到了Knowledge Embedding(对应图中绿色的部分)。
Knowledge Embedding:
由于知识之间是相关的而非独立的,因此作者引入了memory module来计算当前的知识点与其他知识点的相关性,并最终影响到学生知识状态的隐变量,其中知识间的相关性是通过$\beta_{t}^{i}$实现的。如图中标注,k(K维,K表示所有知识点)表示当前时刻题目对应的知识点的one-hot编码,v($d_{k}$维)则是将k进行地位压缩后的编码向量$v_{t}=\mathbf{W}_{\mathbf{k}}^{\mathrm{T}} k_{t}$,通过memory module(本质上是一个$d_{k} \times K$的矩阵),最终$\beta_{t}^{i}$计算公式如下:
最终隐状态表示为:
$H_{t}^{i}=L S T M\left(\widetilde{x}_{t}^{i}, H_{t-1}^{i} ; \theta_{H^{i}}\right)$,
其中$\widetilde{x}_{t}^{i}=\beta_{t}^{i} \hat{x}_{t}$。
结果:
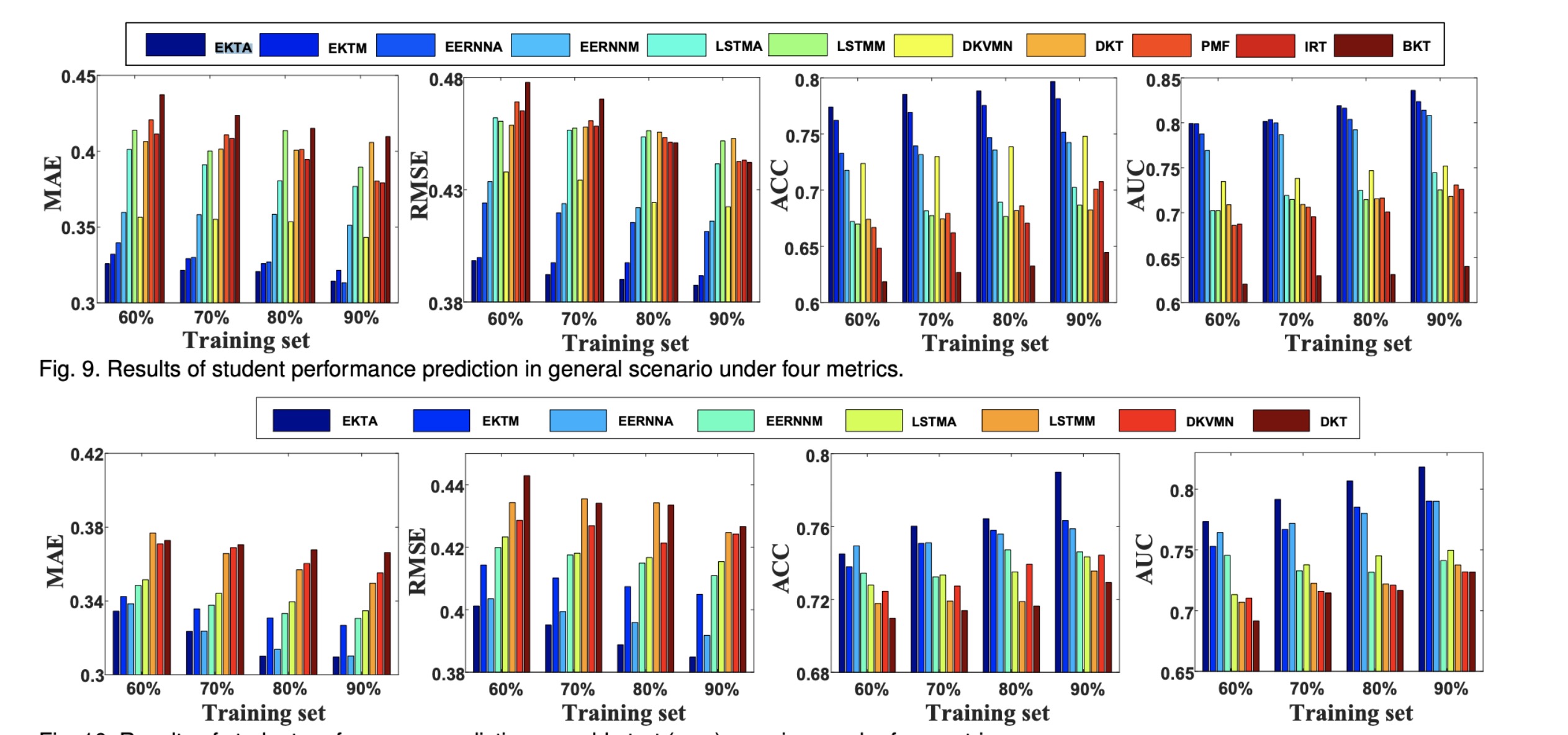
思考:
- EERNN模型为什么只引入题目信息和学生做题记录,为什么不引入知识结构信息?
- EKT和EERNN本质是可以做相同的事情,并且结果表明EKT也由于EERNN相关模型。
- 对应Exercise Embedding为什么采用预训练而不端到端统一到一个model中?