Session-Based Recommendations With Recurrent Neural Networks
这篇是2016 ICLR的一篇文章,考虑到现实生活中更多的推荐场景是基于短期session而不是长期的用户历史,因此如MF等方法就不是很准确,因此本文提出将RNN应用于基于session的推荐系统。
模型
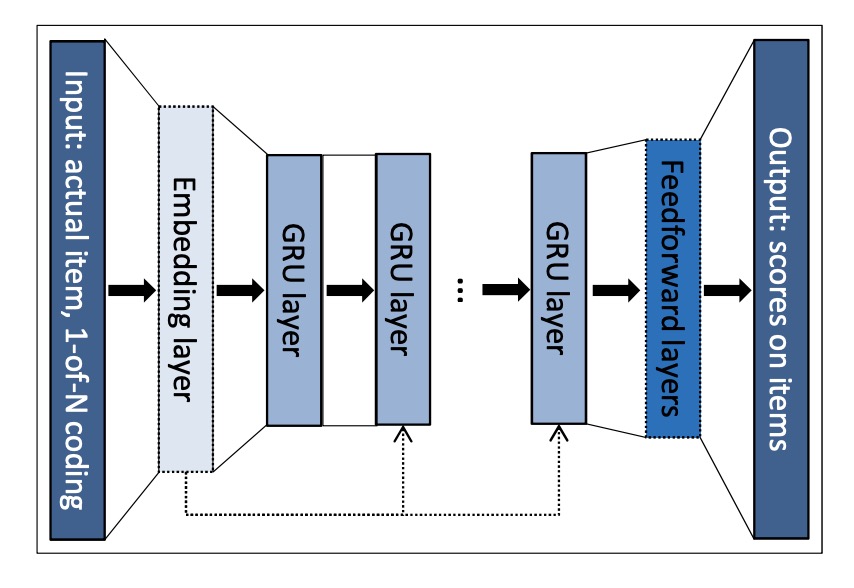
输入对应session内的点击序列,采用one-hot编码,输出为预测的item被点击的概率。为适应推荐任务,作者做了以下几个优化:
session-parallel mini-batches
由于用户一个session内的行为差别很大,比如有的时候只有两个动作,有的时候会有上百个,而我们希望捕捉的是session内的行为模式,因此不希望通过截断来提高训练效率,因此作者提出来session-parrallel mini-batches,即拼接不同的session减少无效计算,具体如下图所示: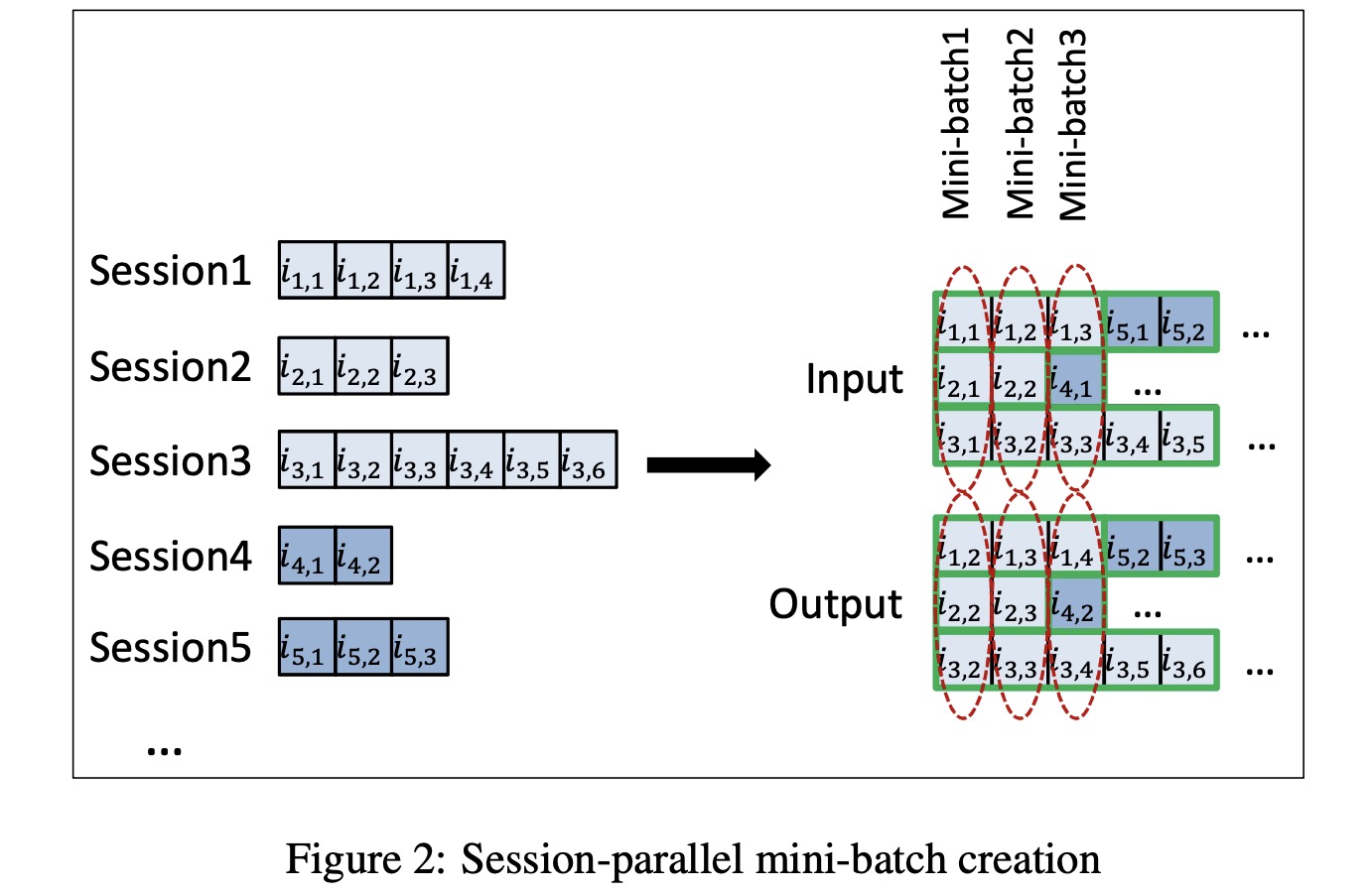
如上图mini-batch3所示,当session2结束后继续接入session4而不是通过padding实现,避免浪费计算。当接入新的session时,需要将对应的隐状态重置。
smapling on the output
由于item数量常常是巨大的,对每一个item在每一个step计算一个得分无疑是巨大的计算量,在实际应用中也会变得不可用。因此作者提出对output进行采样,只对采样得到的正样本和一些负样本计算得分。
对于采样方法,作者采用的是同一个mini-batch中其他sequence的下一个点击的item作为负样本。
ranking loss
排序可以分为pointwise,pairwise和listwise三种,pointwise ranking的损失函数是对单点预测结果和实际之间对差异。pairwise ranking的损失函数是对pair的预测效果和真实之间的差异。listwise可以通过pairwise实现。本文作者尝试了pointwise和pairwise的损失,发现基于pointwise的loss训练出的模型不稳定,因此采用了pairwise的损失。具体包含以下两种:
BPR(Bayesian Personalized Ranking) 一种矩阵分解的方法
$L_{s} = -\frac{1}{N_{S}} \cdot \sum_{j=1}^{N_{S}} \log \left(\sigma\left(\hat{r}_{s, i}-\hat{r}_{s, j}\right)\right)$
其中$N_{S}$为采样大小,$\hat{r}_{s, k}$为给定session下item k的得分。
TOP1 一种正则估计
$L_{s}=\frac{1}{N_{S}} \cdot \sum_{j=1}^{N_{S}} \sigma\left(\hat{r}_{s, j}-\hat{r}_{s, i}\right)+\sigma\left(\hat{r}_{s, j}^{2}\right)$
总结:
文章主要贡献就是将RNN应用于推荐领域(虽然现在看没有什么新意),更具有参考意义的是作者提到的训练上优化的点。
Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
这是发表于RecSys‘16的一篇文章,主要提出结合item信息的基于session的RNN架构。
模型
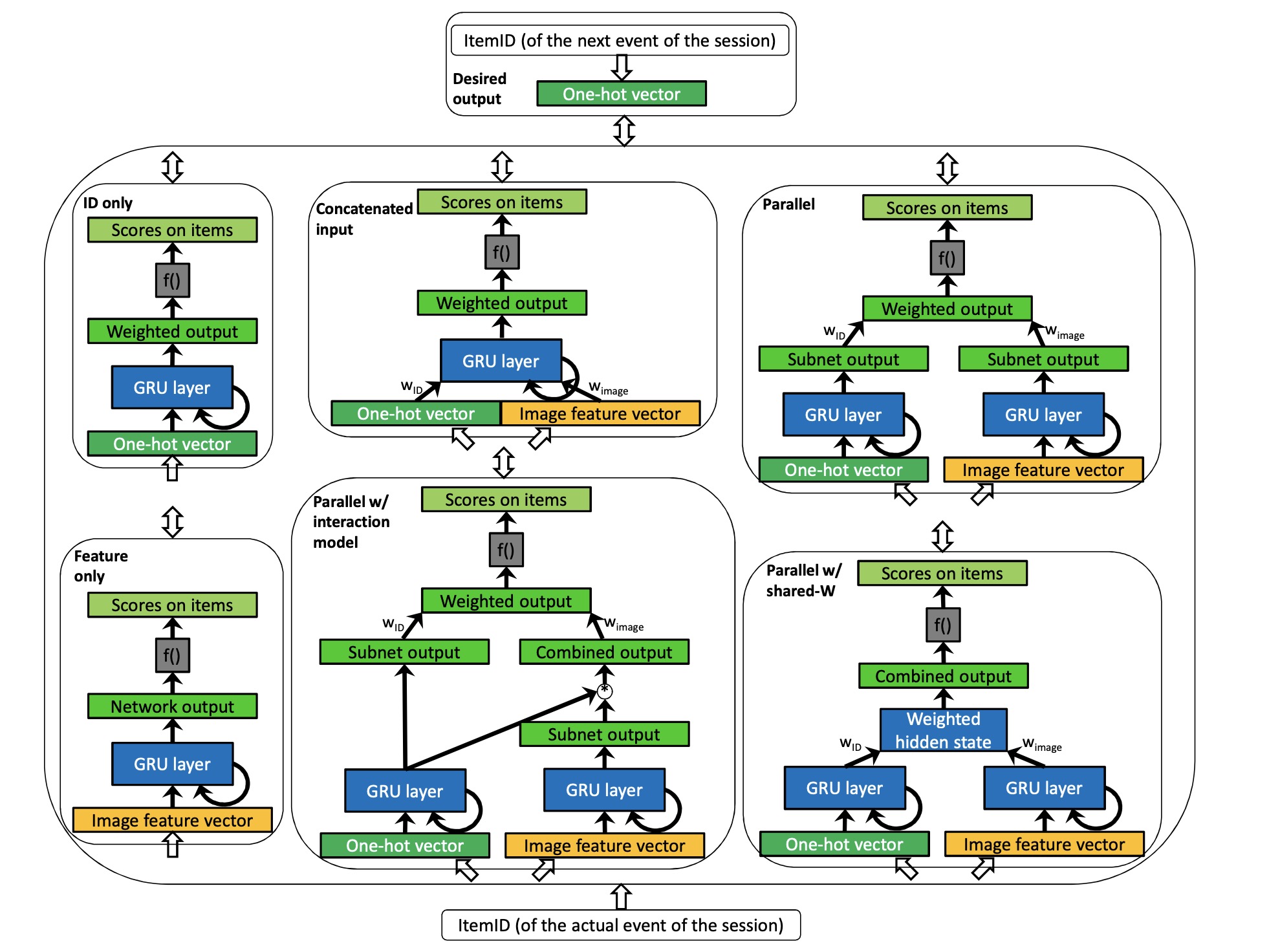
文章所提出的模型架构如上图所示,主要包括以下几个架构:
- Baseline architectures:
- ID only是指只用session 中click item的ID经one-hot作为输入的RNN模型(就是第一篇paper中的模型)。
- feature only是指只用item的image feature作为输入的模型(用item文本信息也是一样的道理)。
- Concatenated input是将ID 和image feature concat作为输入送入模型,这也是大家都能想到的结合item feature的方法了。
- p-RNN architectures:
- Parallel 是将ID和image feature分别送入RNN,隐藏层concat之后做预测。
- Parallel Shared-W 与parallel区别的是共享一个用于计算输出的权重矩阵,整个架构类似来自上下文感知因子分解的pariwise的模型。
- Parallel interaction model 这个架构中 image feature的隐状态会和ID 的隐状态做逐元素相乘后再计算推荐结果(类似上下文感知偏好建模),其中计算输出的权重矩阵不共享。
模型用到的损失函数是上文提到的TOP1损失。
p-RNNs训练
对于p-RNNs的训练,作者提出了以下几个策略:
- Simultaneous: 所有的子图同时训练
- Alternating: 交替训练,如第一个epoch训练ID的子图,第二个epoch训练feature的子图,交替往复直到训练结束。
- Residual: 子图一个接一个的训练,当ID子图训练完成后,feature的子图基于残差继续训练。
- Inrerleaving: 每个mini-batch交替训练。
论文实验结果表示Parallel并行更新item ID和feature的模型效果最好,Parallel Shared-W和Parallel interaction model效果没有很好可能是重复的序列信息加重了模型训练的负担。
总结:
本文主要是提出了几种结合item feature的架构,虽然最终实验结果表明Parallel具有最好的结果,但是面对实际业务其他的架构及训练策略还是具有一定借鉴意义的。
Incorporating Dwell Time in Session-Based Recommendations with Recurrent Neural Networks
本文是RecSys‘17的一篇文章,主要提出将item停留时长考虑进去基于session 的RNN建模。
模型
模型架构与第一篇paper中的架构完全一样,只是在session的构建上,如下图所示: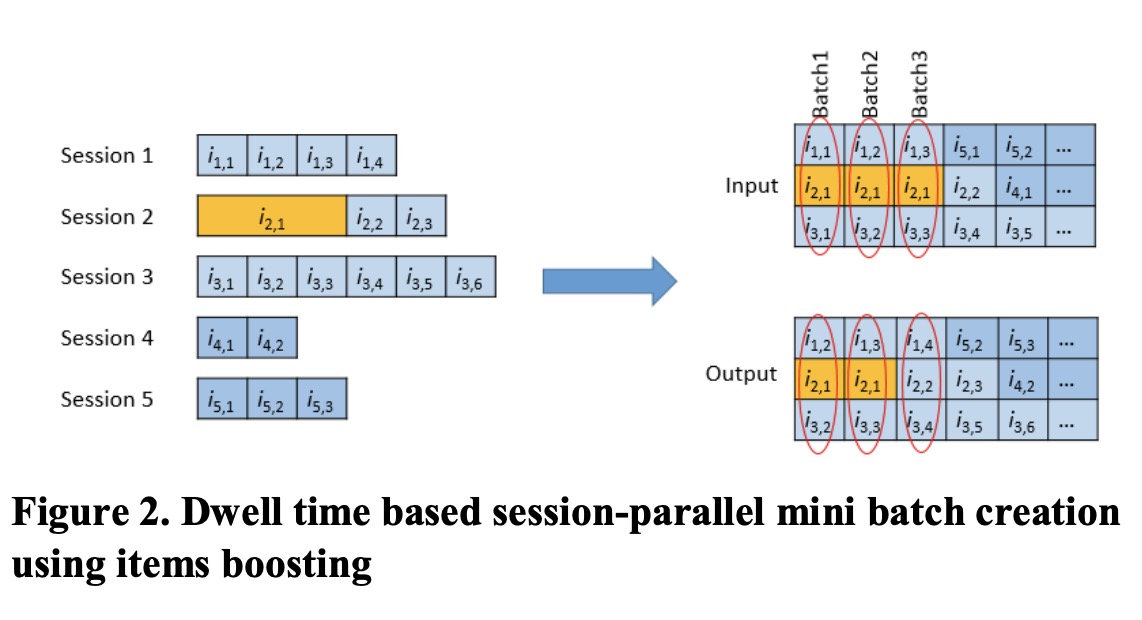
作者认为,用户停留的时间越长表明越感兴趣,将用户在每个item上的停留时间按照单位时间t进行划分,得到如上图中的session。考虑到用户停留时长的session划分能够起到item boosting的效果。
总结
这篇文章短小而精悍,相比于第一篇paper只是考虑到用户时长将session进行划分的不同就可以得到非常大的提升。看到题目标题时,笔者也只是在考虑是将用户停留时长做feature一起送入模型,没想到是采用这样的方式,只是很奇妙的。
Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
这也是RecSys‘17的一篇文章,主要提出层级RNN结构能够捕获session内信息和跨session的信息(如用户兴趣的变迁等)从而做用户的个性化推荐。
模型
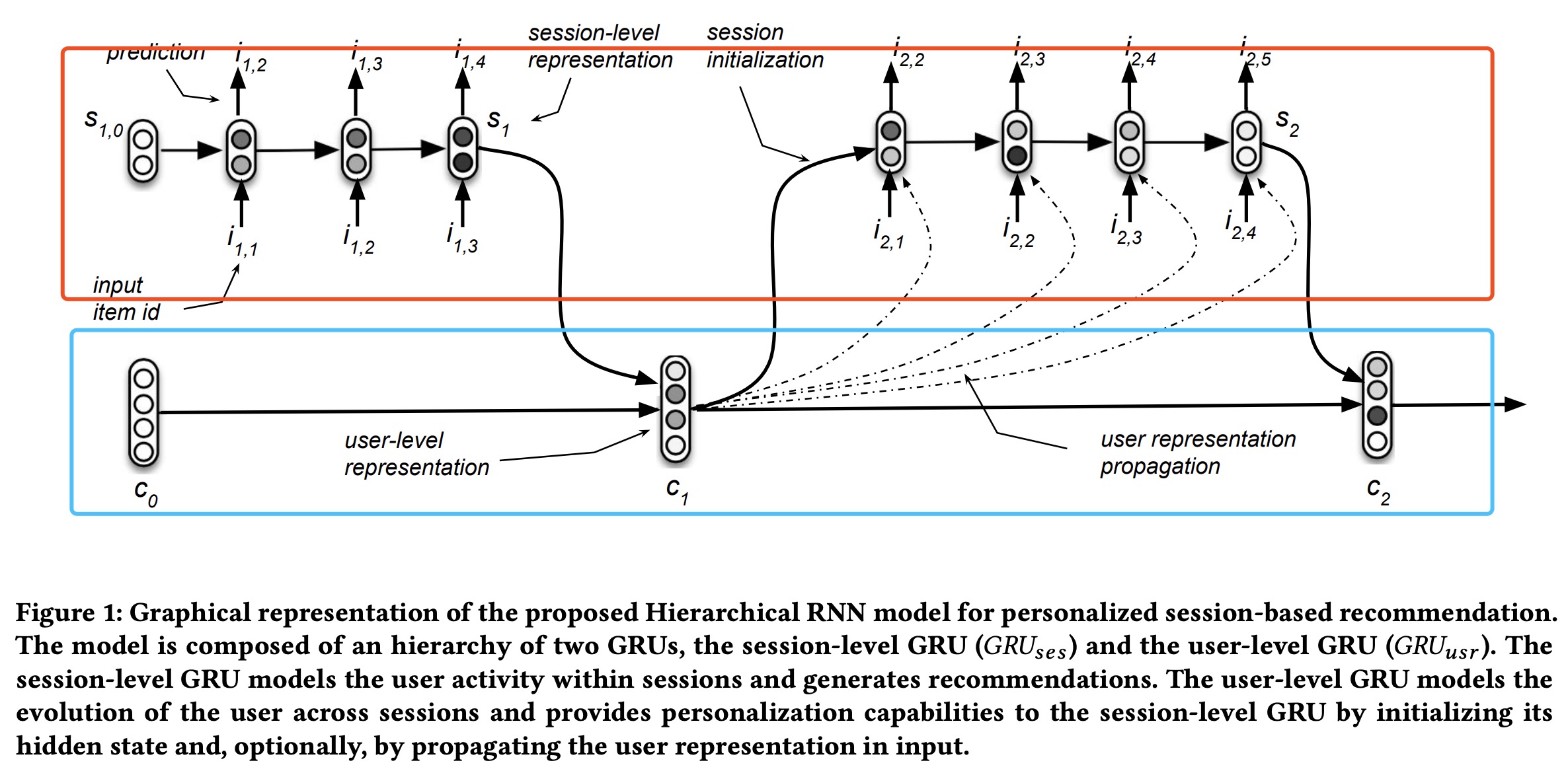
上图为本文提出的HRNN架构图,红框对应session-level GRU,蓝框对应user-level GRU。 session-level GRU输入为session内item ID的one-hot编码,输出为预测的item的score。训练时损失可以采用cross-entrop,BRP或TOP1.
对于一个用户多session时,当一个session结束时,用session-level GRU的输出来计算当前user-level GRU的表示:
$c_{m}=G R U_{u s r}\left(s_{m}, c_{m-1}\right), m=1, \ldots, M_{u}$,
user-levelGRU的表示来初始化下一个session的输入:$s_{m+1,0}=\tanh \left(W_{i n i t} c_{m}+b_{i n i t}\right)$
随着迭代,$s_{m+1, n}=G R U_{s e s}\left(i_{m+1, n}, s_{m+1, n-1}\left[, c_{m}\right]\right), n=1, \ldots, N_{m+1}-1 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ …(1)$
训练是端到端进行的,user-level GRU只有在session结束时才更新。
总结
本文提供了一种可以综合跨session信息的策略,从而可以捕捉到诸如用户兴趣变迁等信息。
When Recurrent Neural Networks meet the Neighborhood for Session-Based Recommendation
这也是RecSys‘17的一篇文章,本文主要在基于session-bases rnn model的基础上,结合了KNN,实验结果显示对推荐结果有了进一步对提升。
模型
如果一个item在和当前item相似的session中出现过,则这个item出现的可能性更大,基于这种考虑,作者提出了基于session-based KNN。
GRU4REC
与论文1中提出的session-based RNN一致
Session-based KNN
根据当前session找到最相近的K个历史session,item i在当前session出现的概率为:
$score_{KNN} ( i , s )=\Sigma_{n \in N_{s}} \operatorname{sim}(s, n) \times 1_{n}(i)$
其中sim(s,n)可以是各种衡量相似度的公式(作者实验得cosine取得最好的结果),$1_{n}(i)=1$指当session n中包含item i为1,否则为0.
Hybird Approach
两个方法综合的方式有switching,cascading和weighted hybirds。作者实验结果表明weighted hybirds方式可以取得最好的结果。
总结
本文提出了一种基于session-based KNN模型,KNN更多的是关注近期数据表现,RNN相对可以捕获更长的序列,混合模型对结果还是会有提升。
Improved Recurrent Neural Networks for Session-based Recommendations
DLRS’16的一篇文章,在GRU4REC(paper1 介绍的session-based RNN)基础上提出的两条提升模型效果的方法,并且提出了一个generalised distillation framework来替代原有模型。
提升模型效果的方法
GRU4REC是对$\mathbf{x}=\left[x_{1}, x_{2}, \ldots, x_{r-1}, x_{r}\right]$这样的session序列做预测,本质是一个分类模型。由于session内数据变化很大,而我们的任务是作出对任意长度都适用的模型。
Data Augument
给定一个session的输入序列$\mathbf{x}$,可以产生出多条训练数据如$\left(\left[x_{1}\right], V\left(x_{2}\right)\right),\left(\left[x_{1}, x_{2}\right], V\left(x_{3}\right)\right), \ldots\left(\left[x_{1}, x_{2}, \ldots, x_{n-1}\right], V\left(x_{n}\right)\right)$,同时用户能存在误点击的操作,因此可以引入dropout的方式来做泛化。总体结果如下图所示: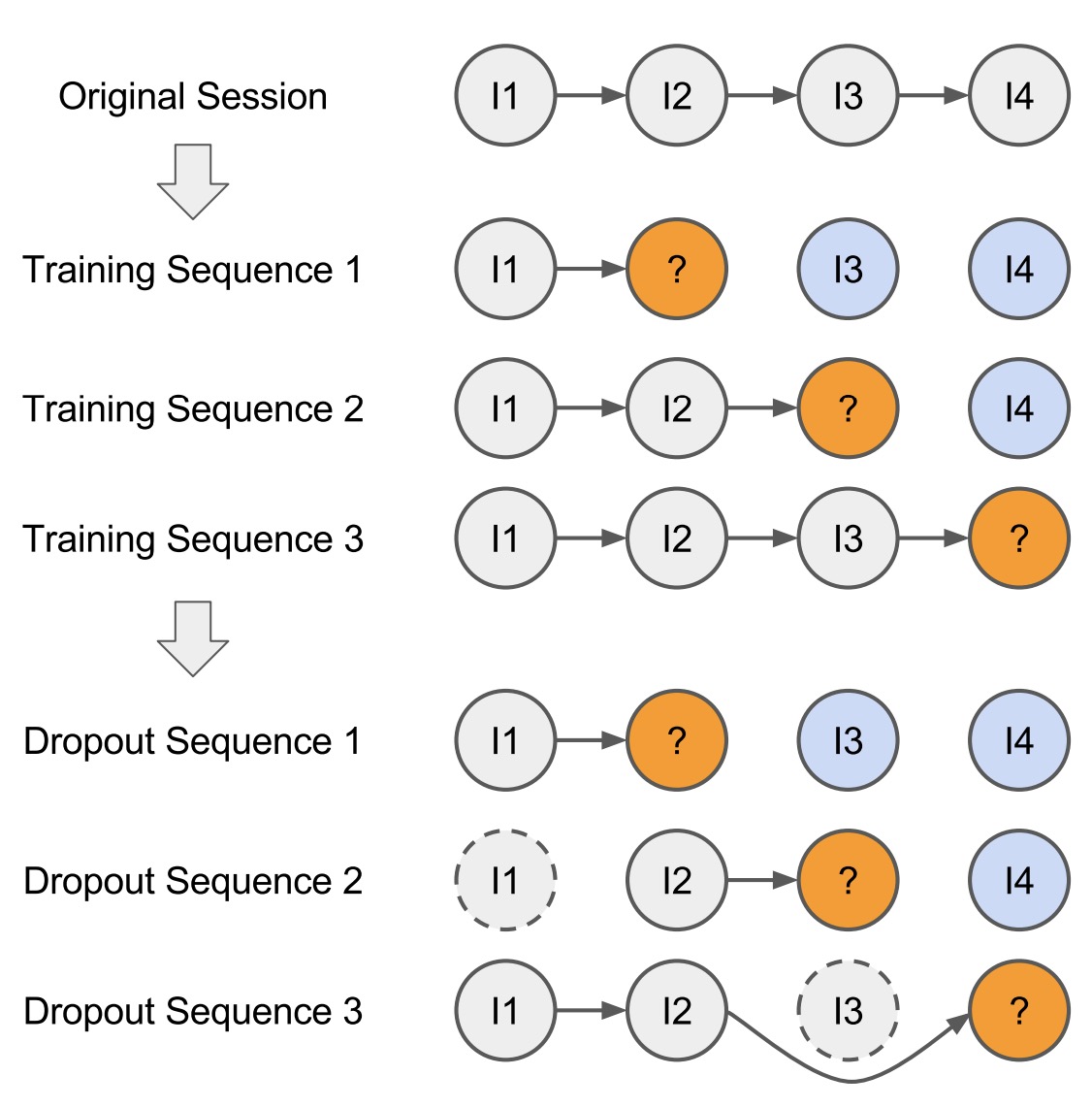
Adapting to temporal changes
机器学习算法的一个基本假设是数据独立同分布的,对于推荐的数据,显然并不是严格成立的:当item被显示时用户才有可能点击,并且用户的行为是随时时间变化的。推荐的任务是根据用户当前的行为预测下一个点击的item,因此应该更关注的是当前的行为序列而不是更早之前的行为。而训练通常会采用全历史行为记录去做模型,因此可能引入偏差。
为缓解上述问题,可以简单的设置一个空间上的门限,大概门限值的记录就可以舍弃。另一种是采用预训练的方法,首先用全量数据做训练,之后再用近期的数据做fine-tune。
Use of privileged information
这部分对应作者提出的generalised distillation framework。给定的序列$x_{1},x_{2}\ldots x_{r-1}$预测$x_{r}$,作者称$x_{r+1},\ldots x_{n}$为privileged information,其对应的privileged sequence 为$x^{}=\left[x_{n}, x_{n-1} \ldots x_{r+2}\right]$。其中n为原始序列的总长度。首先可以以privileged sequence训练teacher model,然后再tune student model,其loss function为:
$(1-\lambda) L\left(M(\mathbf{x}), V\left(x_{n}\right)\right)+\lambda L\left(M(\mathbf{x}), M^{}\left(\mathbf{x}^{}\right)\right)$。其中$\lambda \in[0,1],$M对应student model,$M^{}$为teacher model。
Output embeddings for faster predictions
作者提出可以对item embedding向量做预测,使测试结果更具有泛化意义。loss function此时可以定义为embedding的cosine相似度。此时计算量也可以下降: 从原始的HN变为HD,H为hidden layer nums,N为item个数,D为item的embedding size。
总结
作者提出了2中策略提升原GRU4REC的效果,另外提出了generalised distillation framework来训练一个新的模型,同时将item预测的任务变为预测item embedding。对于直接对item embedding的预测,作者最后也提到,需要优质的item embedding源做label,虽然可以重用上述模型的产出,但是此时的效果又会如何呢?
参考文献
- SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS
- Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations
- Incorporating Dwell Time in Session-Based Recommendations with Recurrent Neural Networks
- Personalizing Session-based Recommendations with
Hierarchical Recurrent Neural Networks - When Recurrent Neural Networks meet the Neighborhood for
Session-Based Recommendation - Improved Recurrent Neural Networks for Session-based Recommendations